


La tecnologia ANPR di Hikvision può essere impiegata in tutto il mondo grazie a soluzioni flessibili e intelligenti basate sul machine learning (AI) per analizzare e identificare qualsiasi targa con grande precisione, affidabilità e rapidità.
La videosorveglianza applicata al controllo dei mezzi di trasporto è sempre più diffusa, sia in ambito gestionale (pagamento parcheggi e pedaggi, controllo accessi ecc.) sia nella sicurezza (rilevamento infrazioni, indagini forensi ecc.).
Esistono varie tecnologie utilizzate per leggere e identificare le targhe degli automezzi (ANPR), che si differenziano per procedura utilizzata, algoritmi impiegati e altri fattori. Non tutti i software ANPR, tuttavia, possono operare a livello globale, perché gli algoritmi o le immagini campione vengono addestrati per riconoscere solo alcune decine di targhe e non le centinaia o migliaia impiegate nei cinque continenti.
La tecnologia ANPR di Hikvision, invece, utilizza sofisticati algoritmi di machine learning per estendere le capacità di riconoscimento del sistema a qualsiasi targa, con un basso margine d’errore.
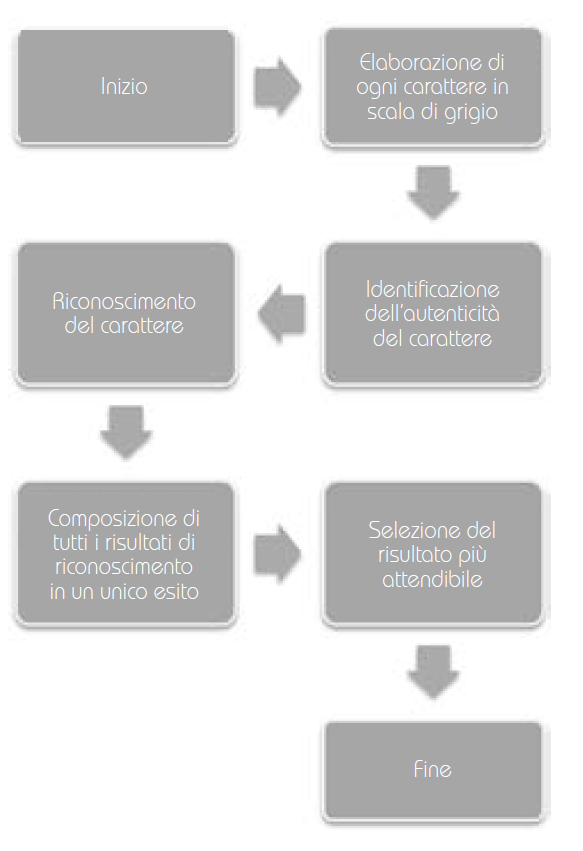
Quattro step per l’identificazione
Uno dei punti di forza della tecnologia ANPR di Hikvision è l’estrazione di numeri, lettere e simboli dalle targhe con isolamento dal resto dell’inquadratura, spesso costellata di elementi che possono ingannare il software di riconoscimento. Gli algoritmi utilizzati dall’azienda permettono invece di rilevare la targa con un rischio di errore minimo, isolando ogni elemento e partizionando i caratteri per poi procedere con il riconoscimento.

La tecnologia non si basa sul colore o sulla struttura dei caratteri delle targhe dei veicoli - come avviene in altri software ANPR che richiedono un lungo lavoro di addestramento (caricamento immagini di targhe da tutto il mondo, specifiche layout ecc.) - ma è in grado di distinguere le targhe “mono-riga” (come quelle europee) e “doppia-riga” (americane, mediorientali ecc.) senza pregiudicare il riconoscimento di ogni singolo elemento grafico e alfanumerico.
La procedura di identificazione si basa su quattro step:
- posizionamento approssimativo,
- filtraggio della targa,
- posizionamento preciso
- post-processing (riconoscimento caratteri).
Posizionamento approssimativo
La procedura di localizzazione approssimativa opera in base al contrasto tra lo sfondo e i caratteri della targa, indipendentemente dalla combinazione di colori (per esempio, sfondo bianco e caratteri neri, sfondo nero e caratteri bianchi, sfondo giallo e caratteri neri ecc.). Il software ANPR scansiona ogni singolo fotogramma del video catturato dalla telecamera di sorveglianza alla ricerca di questi elementi a forte contrasto.

Componenti dei veicoli, arredi urbani, cartellonistica e altri elementi presenti nell’inquadratura possono ingannare il software in questa prima fase, ma si tratta di un’occorrenza perfettamente normale trattandosi della primissima fase di rilevamento.
Filtraggio della targa
Lo step successivo è l’applicazione di un filtro basato su sofisticati algoritmi capaci di discriminare in modo rapido, preciso ed efficace le targhe da qualsiasi altro elemento. Se gli elementi identificativi presenti negli algoritmi confermano che si tratta di una targa reale, si passa allo step successivo – altrimenti il “crop” della ripresa video viene scartato.
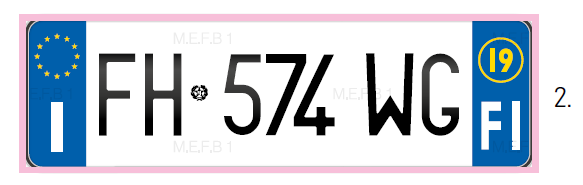
L’immagine catturata dalla telecamera non è quasi mai identica a quella di una targa fotografata di fronte o scannerizzata, perché l’angolo di ripresa può variare di parecchi gradi, l’immagine risulta sfocata per via del movimento ecc.
Posizionamento preciso
Il terzo step consiste nel rilevamento dei contorni della targa, indipendentemente dalla presenza di lettere e numeri di identificazione su una o due righe. Per quest’operazione si utilizza lo stesso metodo (effetto contrasto) di cui sopra: il software esamina lo sfondo, i caratteri e gli altri elementi stabilendo con precisione i bordi reali della targa e definendo l’area da sottoporre ad analisi e riconoscimento.

L’algoritmo di rilevamento dei caratteri permette anche di stabilire quali sono gli elementi identificativi chiave delle targhe composte da due o più righe e ignorare numeri e lettere ininfluenti ai fini della procedura ANPR (anno di immatricolazione, Paese, regione ecc.).
Post-processing e riconoscimento dei caratteri
Completata la fase di delimitazione dei bordi della targa (superiore e inferiore), si passa agli step di post-processing, come il posizionamento dei moduli carattere nell’area d’interesse e il loro riconoscimento.
Esistono vari metodi per delimitare il rettangolo circoscritto dal carattere alfanumerico, ciascuno con i propri vantaggi e svantaggi:
-
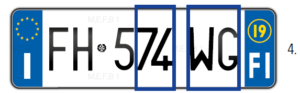
POST-PROCESSING E RICONOSCIMENTO CARATTERI Proiezione verticale: è un metodo che identifica le depressioni delle onde negli spazi tra i caratteri (per individuarli e separarli) osservando le proiezioni. Non è in grado di stabilire dove si trova il bordo sinistro del primo carattere e, pertanto, non va utilizzato come metodo unico ma in combinazione con altri.
- CCL (etichettatura dei componenti collegati): ogni carattere è una regione connessa oppure ha una parte connessa. È possibile estrapolare la regione connessa dall’immagine per ottenere la forma del carattere, ma il rumore presente nell’immagine ripresa potrebbe degradare le regioni di caratteri diversi e interferire con l’identificazione della partizione dei caratteri.
- Corrispondenza modello: si tratta di un metodo utile per individuare esattamente la posizione del carattere e la sua struttura, ma solo dopo aver utilizzato altre applicazioni (come la proiezione verticale). Purtroppo, nel mondo esistono centinaia di targhe con forme e layout differenti, per cui è un metodo poco affidabile.
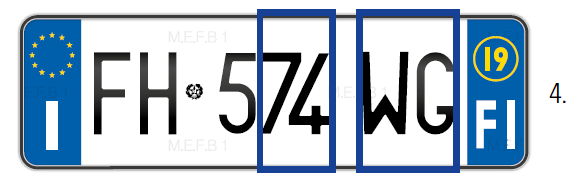
Riconoscimento caratteri con machine learning
L’algoritmo OCR progettato da Hikvision si basa su una rete neurale di apprendimento automatico: è più preciso e affidabile rispetto ai sistemi di riconoscimento tradizionali, perché utilizza un modulo di identificazione dell’autenticità dei caratteri e supporta numeri e lettere di vari alfabeti (inglese, arabo, cinese, coreano, tailandese, giapponese ecc.).
 Una tecnica per cinque continenti
Una tecnica per cinque continenti
Per risolvere il problema dell’universalità dell’algoritmo di partizione dei caratteri, Hikvision ha sviluppato:
- una tecnica avanzata (partizione approssimativa) che combina la proiezione verticale e la CCL per dividere approssimativamente i caratteri;
- un metodo (partizione ad alta precisione) per separare con precisione i caratteri;
- una strategia per identificare i bordi dei caratteri nelle targhe multi-linea e multi-sezione.
Grazie a questo il software dell’azienda può essere applicato su qualsiasi targa nei cinque continenti e non solo in mercati specifici.
Partizione approssimativa
Durante la procedura di partizione approssimativa, Hikvision utilizza innanzitutto la CCL per stimare la larghezza dei caratteri e degli spazi, poi adotta la proiezione verticale per individuare i caratteri e i loro bordi (sinistro e destro).
Partizione ad alta precisione
Poiché la partizione approssimativa può generare errori (come l’unione di due caratteri in uno solo oppure la divisione di un carattere in due), l’azienda ha sviluppato un algoritmo di partizione ad alta precisione, articolato nel seguente modo:
- basandosi su diverse immagini pre-elaborate (a scala di grigio, disegni di contorno ecc.), l’algoritmo confronta i risultati e seleziona quello più attendibile;
- un secondo algoritmo viene utilizzato per identificare i caratteri con larghezza differente; i caratteri risultato della partizione vengono evidenziati all’interno di un rettangolo blu;
- per ovviare al problema per cui i caratteri simili vengono spesso considerati un solo carattere dopo la partizione approssimativa, la tecnologia BAT (Block Analysis Technology, ossia analisi dei blocchi) partiziona ogni carattere migliorando l’affidabilità del riconoscimento.
Lettura targhe multi-linea e multi-sezione
Hikvision ha poi sviluppato una tecnica di analisi delle targhe multi-campo e multi-riga non basata su schemi predefiniti, ma su algoritmi “dinamici” capaci di individuare il campo con meno caratteri (di norma ininfluenti) rispetto a quello con più caratteri (dati identificativi veri e propri) indipendentemente dal loro posizionamento.



 l'analisi targhe.){kind=link}